Defining Table Creates Links Between Tables That Identify A Correspondence
Arias News
Mar 29, 2025 · 7 min read
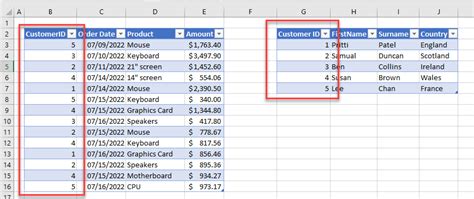
Table of Contents
Defining Tables: Creating Links Between Tables That Identify a Correspondence
Defining tables is a fundamental concept in relational database management systems (RDBMS). It's not just about storing data; it's about structuring that data in a way that allows for efficient retrieval and manipulation. A crucial aspect of this structuring is the ability to create links between different tables, establishing a correspondence between related data. This article delves deep into the concept of defining tables and creating these vital links, exploring various methods and their implications.
Understanding Relational Database Fundamentals
Before diving into table definitions and relationships, let's establish a foundational understanding of RDBMS. A relational database organizes data into tables with rows (records) and columns (attributes). Each table typically represents a specific entity or concept, like customers, products, or orders. The power of RDBMS comes from the ability to connect these tables, avoiding data redundancy and ensuring data integrity. This interconnectedness is achieved through relationships.
Key Concepts:
- Tables: These are the fundamental building blocks, organizing data in a structured format. Each table has a unique name and a defined schema (structure).
- Rows (Records): Each row represents a single instance of the entity represented by the table.
- Columns (Attributes): These represent the specific characteristics or properties of the entity. Each column has a defined data type.
- Relationships: These connections between tables establish how data from different tables relate to each other.
Defining Tables: Structure and Data Types
Defining a table involves specifying its name, columns, and data types for each column. The choice of data types is crucial for data integrity and efficiency. Consider the following example of a Customers table:
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
FirstName VARCHAR(255),
LastName VARCHAR(255),
Email VARCHAR(255) UNIQUE,
Address VARCHAR(255)
);
This SQL statement defines a table named Customers with the following columns:
- CustomerID: An integer (
INT) serving as the primary key, uniquely identifying each customer. ThePRIMARY KEYconstraint ensures uniqueness and prevents duplicate entries. - FirstName, LastName, Email, Address: These columns store customer information using the
VARCHARdata type, which allows for variable-length strings. TheUNIQUEconstraint onEmailensures that no two customers have the same email address.
Establishing Relationships Between Tables
The true power of relational databases emerges when you establish relationships between tables. These relationships allow you to link related data efficiently and avoid redundancy. The most common types of relationships are:
1. One-to-One Relationships:
This type of relationship exists when one record in a table is related to only one record in another table, and vice-versa. For example, a Person table might have a one-to-one relationship with a Passport table, as each person typically has only one passport, and each passport belongs to only one person.
CREATE TABLE Person (
PersonID INT PRIMARY KEY,
FirstName VARCHAR(255),
LastName VARCHAR(255)
);
CREATE TABLE Passport (
PassportID INT PRIMARY KEY,
PersonID INT UNIQUE,
PassportNumber VARCHAR(255),
FOREIGN KEY (PersonID) REFERENCES Person(PersonID)
);
Here, the FOREIGN KEY constraint in the Passport table links it to the Person table through the PersonID column.
2. One-to-Many Relationships:
This is the most prevalent type of relationship. One record in a table can be related to multiple records in another table. For instance, a Customer can place multiple Orders.
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
FirstName VARCHAR(255),
LastName VARCHAR(255)
);
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
OrderDate DATE,
FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID)
);
In this example, a single customer (CustomerID) can have many orders (OrderID). The FOREIGN KEY constraint in the Orders table links to the Customers table.
3. Many-to-Many Relationships:
This relationship exists when multiple records in one table can be related to multiple records in another table. Consider the relationship between Students and Courses. A student can enroll in multiple courses, and a course can have multiple students. This requires an intermediary table, often called a junction table or bridge table.
CREATE TABLE Students (
StudentID INT PRIMARY KEY,
StudentName VARCHAR(255)
);
CREATE TABLE Courses (
CourseID INT PRIMARY KEY,
CourseName VARCHAR(255)
);
CREATE TABLE StudentCourses (
StudentID INT,
CourseID INT,
PRIMARY KEY (StudentID, CourseID),
FOREIGN KEY (StudentID) REFERENCES Students(StudentID),
FOREIGN KEY (CourseID) REFERENCES Courses(CourseID)
);
The StudentCourses table acts as a bridge, linking students and courses. It has composite primary key comprising both StudentID and CourseID, enforcing the uniqueness of student-course combinations.
Choosing the Right Data Types
Selecting appropriate data types is critical for data integrity and efficiency. Using the wrong data type can lead to errors, data loss, or performance issues.
- INT (Integer): For whole numbers.
- VARCHAR (Variable-Length String): For text strings of varying lengths.
- CHAR (Fixed-Length String): For text strings of a fixed length.
- DATE: For dates.
- DATETIME: For dates and times.
- FLOAT/DOUBLE: For floating-point numbers (numbers with decimal points).
- BOOLEAN: For true/false values.
Constraints and Data Integrity
Constraints are rules that enforce data integrity and prevent invalid data from being inserted into the database. Common constraints include:
- PRIMARY KEY: Uniquely identifies each record in a table.
- UNIQUE: Ensures that all values in a column are unique.
- FOREIGN KEY: Establishes a link between tables by referencing the primary key of another table.
- NOT NULL: Prevents null values from being inserted into a column.
- CHECK: Allows you to specify a condition that must be met for a value to be inserted.
Normalization and Database Design
Database normalization is a process of organizing data to reduce redundancy and improve data integrity. It involves breaking down larger tables into smaller, more manageable tables and defining relationships between them. Normalization helps to minimize data inconsistencies and improve the overall efficiency of the database. Different normal forms (1NF, 2NF, 3NF, etc.) represent progressively higher levels of normalization. Proper normalization is crucial for robust database design.
Advanced Relationship Concepts
Beyond the basic relationship types, there are more complex scenarios:
-
Self-referencing Relationships: A table can have a relationship with itself. For example, an
Employeestable might have a self-referencing relationship to represent a management hierarchy, where one employee is the manager of another. -
Recursive Relationships: This is a special type of self-referencing relationship, often used in hierarchical data structures like organizational charts or bill of materials.
-
Inheritance Relationships (Object-Oriented Databases): While not directly part of the relational model, object-oriented databases support inheritance, allowing you to create tables that inherit properties from other tables.
Indexing for Performance Optimization
Indexes are special lookup tables that the database search engine can use to speed up data retrieval. Simply put, an index in SQL is a pointer to data in a table. Indexes significantly improve query performance, especially for large tables. However, overuse of indexes can also hinder performance, so careful consideration is needed when deciding which columns to index.
Data Integrity and Transaction Management
Data integrity is paramount in any database system. Maintaining data integrity involves ensuring accuracy, consistency, and validity of data. Transaction management plays a vital role in achieving data integrity, ensuring that operations either complete successfully as a whole or not at all, preventing partial updates that could corrupt data. ACID properties (Atomicity, Consistency, Isolation, Durability) are crucial for robust transaction management.
Conclusion
Defining tables and establishing relationships between them are fundamental to building efficient and robust relational databases. Understanding the different types of relationships, choosing appropriate data types, enforcing constraints, and applying normalization techniques are essential for successful database design. By mastering these concepts, you can create databases that are reliable, scalable, and well-suited for managing and manipulating large amounts of data effectively. Remember, a well-designed database is the cornerstone of any successful application relying on data persistence and retrieval. Continuous learning and adaptation to evolving database technologies are crucial for staying ahead in this dynamic field.
Latest Posts
Related Post
Thank you for visiting our website which covers about Defining Table Creates Links Between Tables That Identify A Correspondence . We hope the information provided has been useful to you. Feel free to contact us if you have any questions or need further assistance. See you next time and don't miss to bookmark.
